Introducción a la IA: LLMs, asistentes y cómo usarlos bien
Qué son los modelos de lenguaje, cómo funcionan por dentro y cómo sacarles provecho como programador sin perder tu criterio.
La inteligencia artificial está en todos lados. Te escribe emails, genera imágenes, resume reuniones y ahora también escribe código. Pero si le preguntas a diez programadores qué piensan de la IA, vas a obtener diez respuestas diferentes — desde “es el fin de nuestra profesión” hasta “es solo una herramienta más”.
La verdad, como casi siempre, está en el medio. La IA no va a reemplazar programadores. Pero los programadores que usan bien la IA van a reemplazar a los que no. En esta guía vas a entender qué son los LLMs, cómo funcionan, y cómo usarlos para ser mejor desarrollador sin delegar tu pensamiento crítico.
¿Qué es la inteligencia artificial?
La inteligencia artificial (IA) es un campo de la computación que busca crear sistemas capaces de realizar tareas que normalmente requieren inteligencia humana: entender lenguaje, reconocer patrones, tomar decisiones, resolver problemas.
Pero “IA” es un término paraguas enorme. Dentro de él hay muchas cosas diferentes:
- Machine Learning: algoritmos que aprenden patrones de datos
- Computer Vision: sistemas que “ven” e interpretan imágenes
- Procesamiento de lenguaje natural (NLP): sistemas que entienden y generan texto
- Robótica: sistemas que interactúan con el mundo físico
- LLMs: modelos de lenguaje que generan texto coherente
Nosotros nos vamos a centrar en los LLMs, que son la forma de IA que más impacta el trabajo de un programador.
¿Qué es un LLM?
Un LLM (Large Language Model, o Modelo de Lenguaje Grande) es un sistema de IA entrenado para predecir qué palabra viene después en una secuencia de texto. Suena simple, pero esa capacidad de predicción, escalada a billones de parámetros, produce algo que parece comprensión real.
Cómo funciona (sin matemáticas)
Imagina que estás jugando un juego donde te doy palabras y tú adivinas la siguiente:
"El gato está sobre la..." → "mesa"
"Para ordenar una lista en Python usas..." → "sort()"Un LLM hace exactamente esto, pero a una escala absurda:
- Entrenamiento: lee prácticamente todo el texto público de internet — libros, artículos, código, foros, documentación. Aprende patrones de cómo se usa el lenguaje.
- Parámetros: tiene billones de “perillas” internas que ajustó durante el entrenamiento para mejorar sus predicciones.
- Inferencia: cuando le escribes un prompt, usa todo lo que aprendió para generar la respuesta más probable, palabra por palabra.
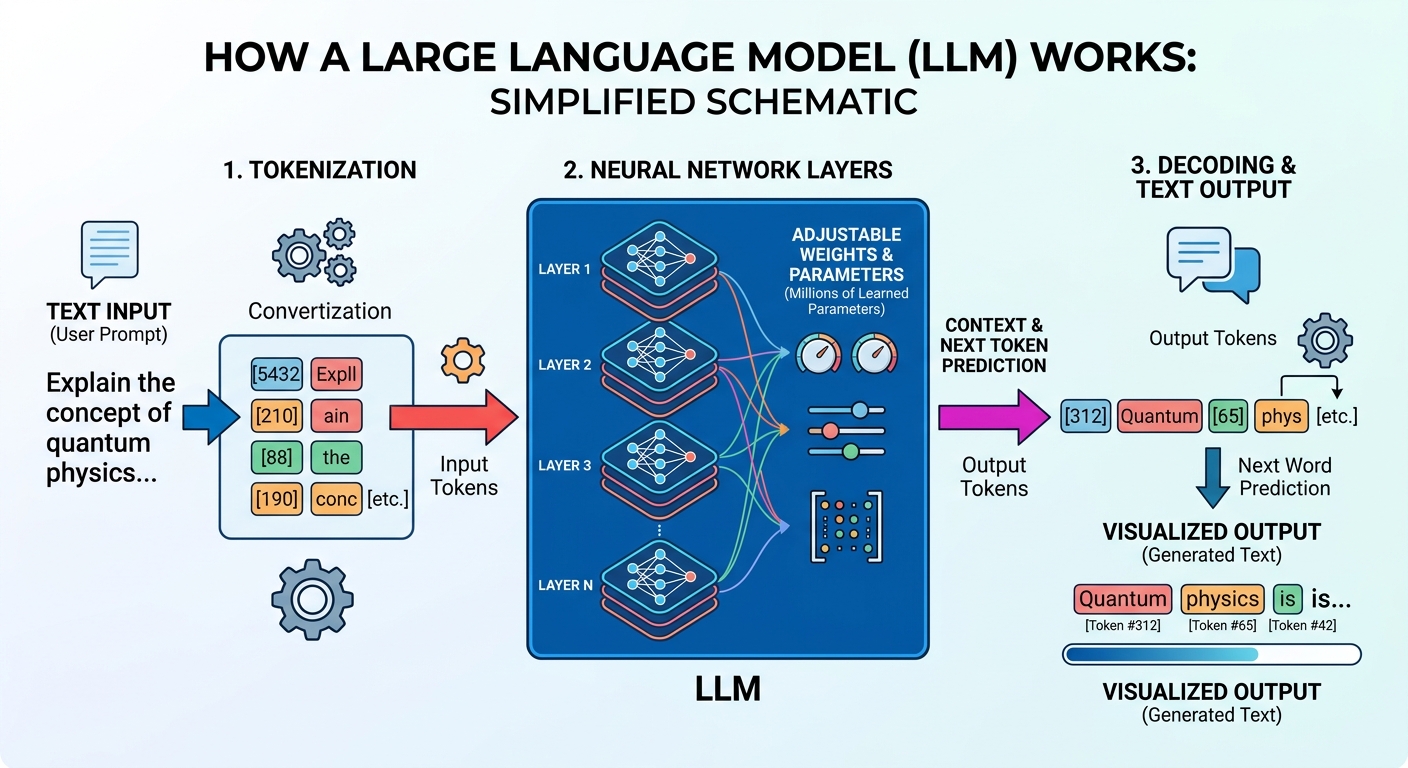
Así funciona un LLM por dentro: recibe texto de entrada, lo procesa a través de capas de red neuronal y genera texto de salida token por token.
Lo que un LLM NO es
Es importante entender esto para no tener expectativas irreales:
- No “piensa” como un humano. No tiene creencias, deseos ni conciencia.
- No “sabe” cosas en el sentido humano. Predice patrones basándose en lo que leyó durante el entrenamiento.
- No es infalible. Puede inventar datos, citar fuentes inexistentes o dar código que no funciona. Esto se llama alucinación.
- No tiene memoria entre conversaciones (a menos que el sistema la implemente explícitamente).
Los principales modelos y asistentes
ChatGPT (OpenAI)
El que popularizó todo. Basado en los modelos GPT (Generative Pre-trained Transformer). Tiene versiones gratuitas y de pago. Es el más conocido y probablemente el más versátil.
Claude (Anthropic)
Conocido por ser más cuidadoso con instrucciones largas, mejor razonando sobre código y con un contexto más amplio (puede procesar documentos enteros). Muy popular entre programadores.
Gemini (Google)
Integrado con el ecosistema de Google. Bueno para búsquedas en tiempo real y tareas que requieren acceso a información actualizada.
Copilot (GitHub/Microsoft)
Integrado directamente en VS Code y otros editores. Sugiere código mientras escribes, completa funciones y puede responder preguntas sobre tu códigobase.
Los modelos chinos: la competencia que cambió el juego
Mientras OpenAI y Anthropic dominaban los titulares, empresas chinas estaban construyendo modelos que no solo compiten en calidad sino que en muchos casos superan a sus contrapartes occidentales — y lo hacen a una fracción del costo, la mayoría open source.
DeepSeek
DeepSeek (High-Flyer AI) es probablemente el modelo chino más conocido internacionalmente. Su modelo DeepSeek-V3 ofrece un rendimiento de 60 tokens/segundo — 3 veces más rápido que generaciones anteriores. La familia incluye:
- DeepSeek-V3.1: arquitectura híbrida de razonamiento que permite modos “thinking” y “non-thinking” en un solo modelo. Optimizado para agentes con scores significativos en SWE-bench y Terminal-bench.
- DeepSeek-R1: modelo de razonamiento puro, mejorado en la versión R1-0528 con menos alucinaciones, soporte para JSON output y function calling.
- DeepSeek-V4: la última generación, integrada directamente en GitHub Copilot como extensión.
- DeepSeek Coder: especializado en generación y comprensión de código.
Lo que los hace diferentes: todos sus modelos son open source, con precios de API dramáticamente más bajos que OpenAI (más de 50% de reducción en versiones recientes). DeepSeek demostró que no necesitas ser una empresa de Silicon Valley para construir modelos de primer nivel.
Qwen (Alibaba)
Qwen es la familia de modelos de Alibaba Group. La última generación, Qwen3.6, incluye variantes como Qwen3.6-Plus, Qwen3.6-Max y Qwen3.6-27B. Qwen3.6-Plus es el modelo que estás usando ahora mismo para leer esta guía.
Características destacadas de Qwen3.6:
- Contexto de hasta 256K tokens en Qwen3.6-Plus, con soporte nativo para imágenes y reconocimiento de video.
- Modo de razonamiento (thinking): puede activar pensamiento paso a paso para tareas complejas.
- Caching de contexto: reduce costos y latencia cuando reutilizas el mismo contexto en múltiples requests.
- 100+ idiomas: soporte masivo para aplicaciones internacionales.
- Precios competitivos: Qwen3.6-Plus cuesta aproximadamente $0.28 por millón de tokens de input y $1.66 por millón de output — una fracción de lo que cobran OpenAI o Anthropic.
- Disponible en OpenRouter como
qwen/qwen3.6-plusy también directamente via DashScope (Alibaba Cloud).
La familia Qwen también incluye modelos anteriores como Qwen3 (Dense y MoE), Qwen3-Coder (especializado en código) y Qwen3.5-Omni (multimodal completo). Los modelos open source van desde 1.8B hasta 72B+ parámetros, lo que significa que puedes elegir el modelo que cabe en tu hardware.
Kimi (Moonshot AI)
Kimi de Moonshot AI se destaca por su enfoque en contexto largo y capacidades multimodales. El modelo más reciente, Kimi K2.6, es un modelo de 1 trillón de parámetros (MoE) que logra resultados líderes en benchmarks como Humanity’s Last Exam, SWE-Bench Pro y DeepSearchQA.
Lo que hace especial a Kimi:
- Soporte multimodal completo: texto, imágenes y video como input. Puedes enviarle clips de video y el modelo los analiza.
- Contexto de hasta 256K tokens: procesa documentos enteros, códigobases grandes o sesiones largas sin perder contexto.
- Modos thinking y non-thinking: como los demás modelos chinos modernos.
- Agentes nativos: diseñado específicamente para tareas de agentic coding con tool use avanzado.
Kimi K2.5 es open source, lo que significa que puedes descargarlo y correrlo localmente si tienes el hardware.
GLM (Zhipu AI)
La serie GLM (General Language Model) de Zhipu AI está diseñada específicamente para aplicaciones de agentes inteligentes. La evolución reciente va de GLM-4.5 → GLM-4.7 → GLM-5 → GLM-5.1.
GLM-5.1 es el flagship actual con avances significativos en:
- Agentic coding: supera a GLM-5 en benchmarks como SWE-Bench Pro, NL2Repo y Terminal-Bench 2.0.
- Optimización a largo plazo: mejor juicio con problemas ambiguos y alta productividad en conversaciones largas.
- 744B parámetros con DeepSeek Sparse Attention (DSA) para reducir costos de deployment manteniendo contexto largo.
- Interleaved Thinking: el modelo piensa antes de responder, con opción de “Preserved Thinking” que mantiene el razonamiento entre turnos.
- Contexto de hasta 200K tokens.
GLM-5 (la generación anterior) ya representó un salto masivo: de 355B a 744B parámetros, 28.5T tokens de pre-entrenamiento, y el top rank entre modelos open source en Vending Bench 2 (planificación y gestión de recursos a largo plazo).
GLM-4.5-Air sigue disponible como versión compacta con 106B parámetros totales y solo 12B activos, ideal para deployment eficiente. Disponible en OpenRouter como z-ai/glm-5.1.
¿Por qué importan los modelos chinos?
- Open source: la mayoría publica sus pesos públicamente. Puedes descargarlos, modificarlos y correrlos localmente.
- Precio: las APIs chinas cuestan una fracción de las occidentales. DeepSeek redujo sus precios más de 50% en 2025.
- Innovación: arquitecturas como MoE, thinking modes y multimodalidad aparecieron primero o se perfeccionaron en modelos chinos.
- Privacidad: al poder correrlos localmente, tus datos no salen de tu máquina.
Portales de modelos: OpenRouter y agregadores
No necesitas elegir un solo proveedor. Plataformas como OpenRouter te dan acceso a cientos de modelos a través de una sola API.
OpenRouter
OpenRouter es un API unificada que conecta con más de 300 modelos de diferentes proveedores. En lugar de integrar la API de OpenAI, Anthropic, Google y cada modelo chino por separado, integras OpenRouter una vez y accedes a todos.
Ventajas principales:
- Un solo endpoint:
https://openrouter.ai/api/v1compatible con el formato de OpenAI. Si tu código ya usa la API de OpenAI, cambiar a OpenRouter es cambiar solo la URL y la API key. - Modelos gratuitos: OpenRouter ofrece varios modelos completamente gratis con el sufijo
:free. Puedes usarlos sin pagar un centavo, perfectos para experimentar y aprender. Ejemplos:qwen/qwen3.6-plus:free,deepseek/deepseek-v3:free,google/gemini-2.0-flash-exp:free. - Modelos de pago: los modelos premium (GPT-4o, Claude Sonnet, etc.) se cobran por token usado. Los precios varían por modelo y proveedor, pero en general los modelos chinos cuestan una fracción de los occidentales. OpenRouter muestra el precio de cada modelo antes de usarlo.
- Balanceo por precio: OpenRouter distribuye automáticamente tu request al proveedor más barato disponible para cada modelo.
- Fallback automático: si un proveedor falla, OpenRouter cambia transparentemente al siguiente sin que tu aplicación se entere.
- Prioriza throughput o precio: puedes configurar si te importa más la velocidad o el costo.
- Crédito inicial: al crear una cuenta nueva, OpenRouter te da un pequeño crédito gratuito para probar modelos de pago sin poner tu tarjeta de inmediato.
Ejemplo de uso con la API:
import requests
url = "https://openrouter.ai/api/v1/chat/completions"
headers = {"Authorization": "Bearer TU_API_KEY"}
response = requests.post(url, headers=headers, json={
"model": "deepseek/deepseek-v3",
"messages": [{"role": "user", "content": "Explica qué es una API REST"}]
})
print(response.json())Ejemplo con el SDK de TypeScript:
import { OpenRouter } from "@openrouter/sdk";
const openRouter = new OpenRouter({
apiKey: process.env.OPENROUTER_API_KEY,
});
const result = await openRouter.models.list();
// Accede a cientos de modelos desde un solo lugarLos IDs de modelo siguen el formato proveedor/nombre-modelo, por ejemplo:
anthropic/claude-sonnet-4openai/gpt-4odeepseek/deepseek-v4-proqwen/qwen3.6-plusmoonshotai/kimi-k2.6z-ai/glm-5.1
Otros agregadores
- Groq: inference ultra-rápido para modelos open source como Llama y Mixtral.
- Together AI: plataforma para correr y fine-tunear modelos open source.
- Fireworks AI: inference optimizado para modelos como Qwen y Llama.
¿Qué es un token y cuánto cuesta?
Antes de usar modelos de pago, necesitas entender cómo se cobra: por token.
¿Qué es un token?
Un token es la unidad básica que procesan los LLMs. No es exactamente una palabra, pero puedes pensar en ello como aproximadamente ¾ de una palabra en inglés o ~1.5 caracteres en español.
Algunas reglas prácticas:
- 100 tokens ≈ 75 palabras en inglés
- 1000 tokens ≈ 1-2 páginas de texto
- El contexto cuenta: tanto tu prompt como la respuesta del modelo se cuentan en tokens
El modelo procesa tu input (tokens de entrada), genera su respuesta (tokens de salida), y te cobran por ambos.
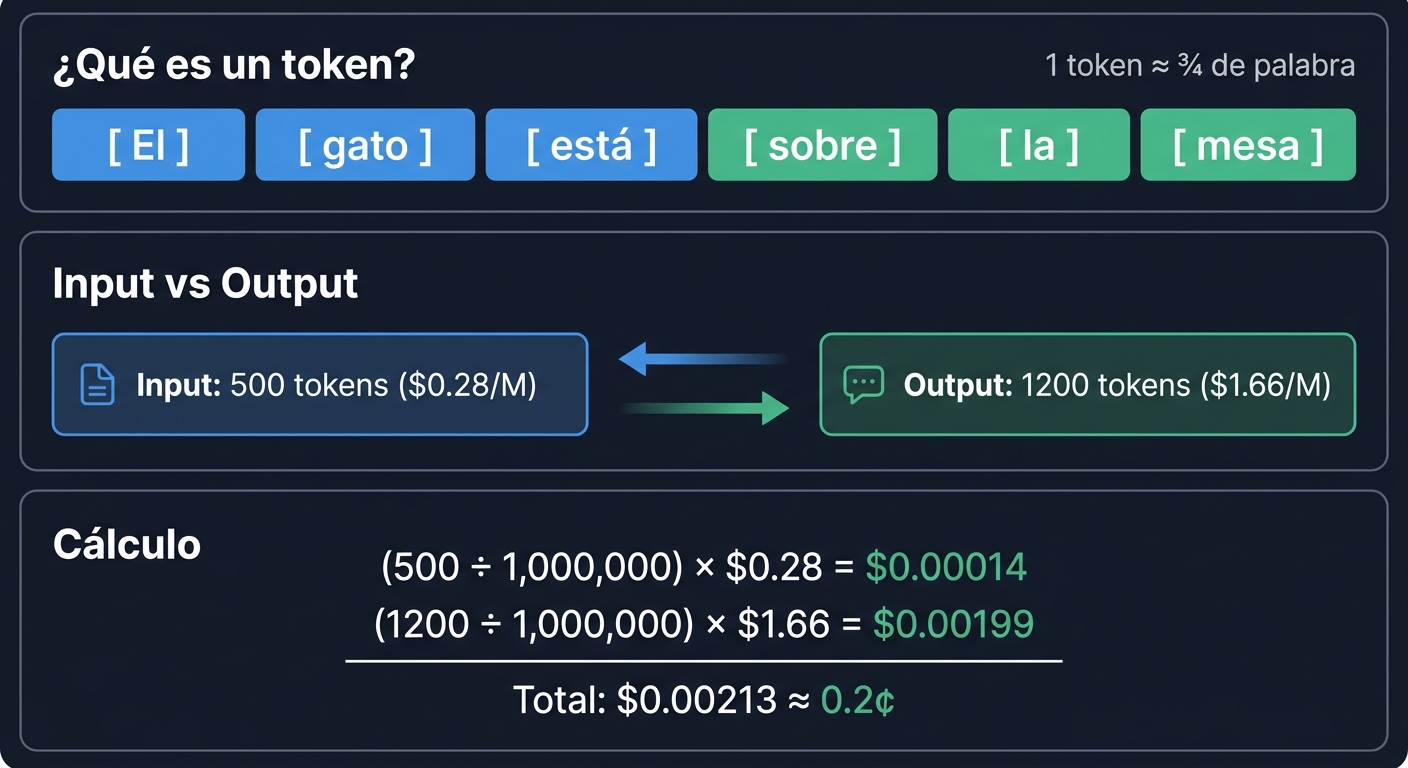
Así se desglosa el cobro por tokens: tu prompt (input) y la respuesta del modelo (output) se cuentan por separado, cada uno con su propio precio.
Cómo se calcula el precio
Las APIs cobran por millón de tokens (1M tokens). Los precios se dividen en dos categorías:
- Input (prompt): lo que tú envías al modelo — generalmente más barato
- Output (respuesta): lo que el modelo genera — generalmente más caro porque requiere más cómputo
La fórmula es simple:
Costo = (tokens_input / 1_000_000) * precio_input + (tokens_output / 1_000_000) * precio_outputEjemplo práctico
Digamos que usas Qwen3.6-Plus (precios aproximados en DashScope):
- Input: $0.28 por 1M tokens
- Output: $1.66 por 1M tokens
Haces una conversación donde:
- Tu prompt tiene 500 tokens (una pregunta con código)
- La respuesta tiene 1200 tokens (explicación detallada)
Costo input: (500 / 1_000_000) * $0.28 = $0.00014
Costo output: (1200 / 1_000_000) * $1.66 = $0.001992
─────────────────────────────────────────
Total: $0.002132 (aproximadamente 0.2 centavos de dólar)Con 1 dólar podrías hacer ~470 conversaciones de ese tamaño con Qwen3.6-Plus.
Comparación de precios (por 1M tokens)
| Modelo | Input | Output | Notas |
|---|---|---|---|
| Qwen3.6-Plus | $0.28 | $1.66 | Muy económico |
| DeepSeek-V3 | $0.27 | $1.10 | El más barato de los top |
| GLM-5.1 | $0.14 | $0.56 | Extremadamente barato |
| Claude Sonnet 4 | $3.00 | $15.00 | ~10x más caro que Qwen |
| GPT-4o | $2.50 | $10.00 | ~6x más caro que Qwen |
Los modelos chinos cuestan entre 5 y 10 veces menos que sus equivalentes de OpenAI o Anthropic. Y si usas las versiones :free en OpenRouter, el costo es cero.
Context caching: el truco para ahorrar
Muchos providers (incluyendo Qwen y DeepSeek) ofrecen context caching. Si envías el mismo contexto repetidamente (por ejemplo, las instrucciones de tu sistema o un archivo de código que no cambia), los tokens cacheados se cobran hasta un 90% menos.
Esto es especialmente útil si trabajas con:
- System prompts largos
- Códigobases que no cambian entre requests
- Documentos de referencia que usas constantemente
Cómo controlar tu gasto
- Monitorea el uso: OpenRouter y DashScope muestran cuántos tokens usaste y cuánto costó cada request.
- Usa modelos gratuitos para experimentar: los
:freede OpenRouter son perfectos para aprender sin gastar. - Sé eficiente con tus prompts: no envíes contexto innecesario. Cada token extra cuesta dinero.
- Pon límites: algunas plataformas te permiten setear un límite de gasto máximo.
Modelos open source para correr localmente
Si prefieres no depender de APIs en la nube, puedes ejecutar modelos en tu propia computadora:
- Llama (Meta): la familia de modelos open source más popular.
- Mistral (Mistral AI): modelos eficientes y de alta calidad.
- Qwen (Alibaba): disponible en tamaños desde 1.8B hasta 72B+ parámetros; Qwen3.6-Plus es el flagship comercial.
- DeepSeek: todos sus modelos son open source, incluyendo V3.1 y R1.
- Kimi K2.5: open source, 1T de parámetros en arquitectura MoE.
- GLM-5.1: open source con 744B parámetros y Sparse Attention, diseñado para agentes.
Para correrlos localmente, herramientas como Ollama, LM Studio o vLLM hacen que sea cuestión de un comando.
Cómo usar la IA como programador
La IA puede ayudarte en prácticamente cada etapa del desarrollo. Aquí van los usos más productivos:
1. Explicar conceptos
Prompt: "Explícame qué es una API REST como si tuviera 15 años.
Usa una analogía del mundo real y dame un ejemplo en Python."Esto es especialmente útil cuando estás aprendiendo algo nuevo y la documentación oficial es muy técnica.
2. Debuggear código
Prompt: "Este código debería devolver [1, 2, 3] pero devuelve [1, 2, 2].
¿Qué está mal? No me des la solución directa, dame pistas."La IA es excelente encontrando bugs porque puede ver patrones que tú pasaste por alto.
3. Generar código boilerplate
Prompt: "Crea una función en Python que lea un archivo CSV,
filtre las filas donde la columna 'edad' sea mayor a 18,
y devuelva una lista de diccionarios."El boilerplate (código repetitivo y estructural) es donde la IA brilla. Te ahorra tiempo en lo mecánico para que te concentres en lo importante: la lógica de negocio.
4. Revisar y mejorar código
Prompt: "Revisa este código y sugiere mejoras en:
- Legibilidad
- Manejo de errores
- Eficiencia
Explica cada sugerencia."5. Escribir tests
Prompt: "Escribe tests unitarios para esta función.
Incluye casos normales, edge cases y casos de error."6. Traducir entre lenguajes
Prompt: "Convierte esta función de Python a TypeScript,
manteniendo la misma lógica y agregando tipos apropiados."Prompt engineering básico
La calidad de la respuesta depende directamente de la calidad de tu prompt. Aquí van reglas prácticas:
Sé específico
❌ "Hazme una web"
✅ "Crea una página HTML con Tailwind CSS que tenga un header con logo,
una sección hero con título y subtítulo, y un grid de 3 tarjetas con
imagen, título y descripción."Da contexto
❌ "¿Por qué falla?"
✅ "Estoy usando Python 3.12 con FastAPI. Esta ruta POST recibe un JSON
con 'nombre' y 'email', pero devuelve error 500. Aquí está el código
y el traceback completo."Pide el formato que necesitas
"Responde en formato de lista con código Python."
"Explica paso a paso como si fuera principiante."
"Dame solo el código, sin explicación."Itera
La primera respuesta rara vez es perfecta. Haz follow-up:
"Eso funciona, pero ¿puedes hacerlo sin usar recursión?"
"Explícame la línea 5 con más detalle."
"¿Hay una forma más eficiente de hacer esto?"Los límites de la IA
Alucinaciones
Los LLMs inventan información con confianza. Pueden citar APIs que no existen, bibliotecas inexistentes o datos históricos falsos. Siempre verifica:
❌ "ChatGPT dijo que esta biblioteca existe" → No existe
✅ Verifiqué en la documentación oficial → Sí existeCódigo desactualizado
Los modelos tienen una fecha de corte de entrenamiento. Pueden sugerir APIs deprecated o patrones que ya no se usan.
No entiende tu códigobase
A menos que le des el contexto completo, la IA no sabe cómo está estructurado tu proyecto, qué convenciones usas o qué decisiones arquitectónicas tomaste.
Sesgos y patrones aprendidos
Los LLMs reflejan los patrones de los datos con los que fueron entrenados. Si la mayoría del código en internet tiene malas prácticas, la IA puede sugerirlas.
Un poco de historia: de Turing a los transformers
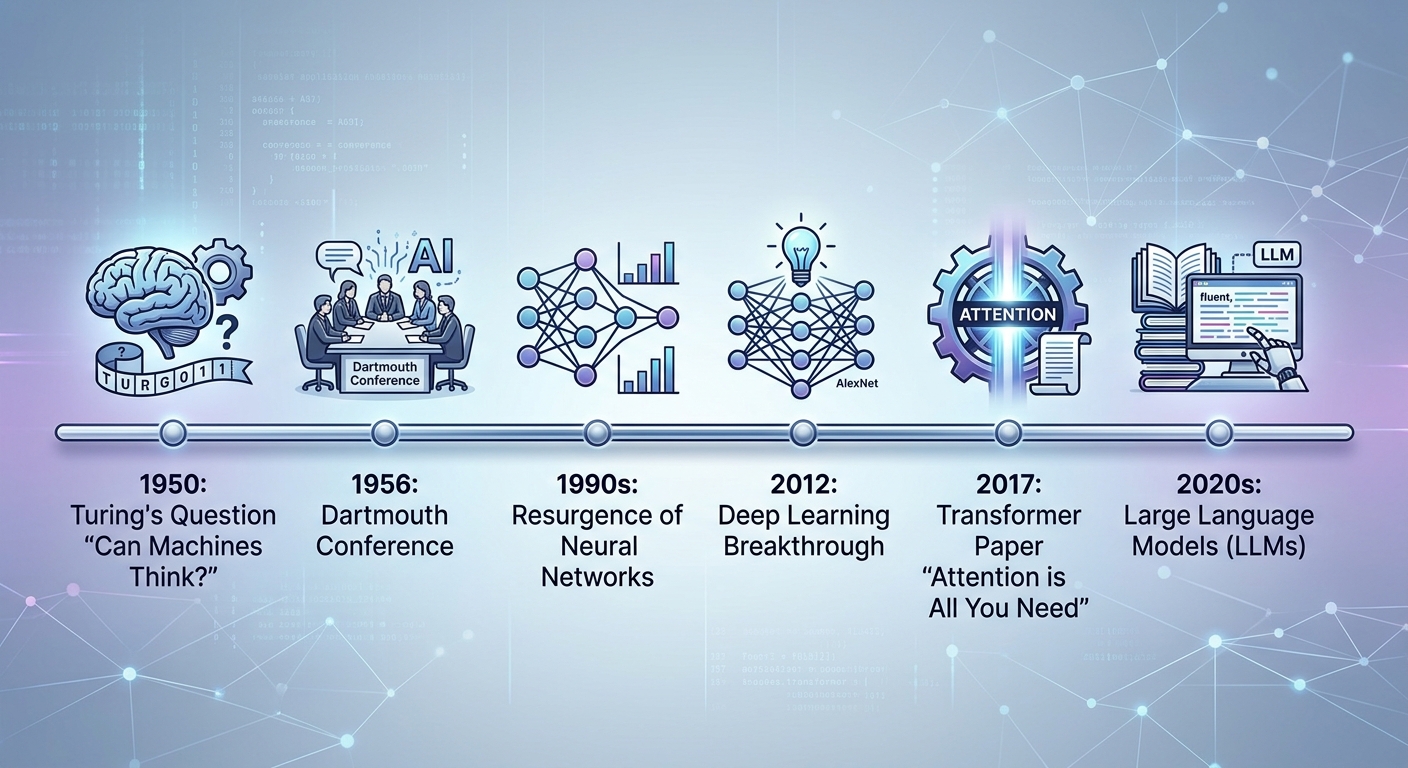
Línea de tiempo de la IA: de la pregunta filosófica de Turing a los transformers que impulsan los LLMs modernos.
La idea de máquinas que “piensan” es antigua, pero la IA como campo científico nació en 1950 con Alan Turing y su pregunta: “¿Pueden pensar las máquinas?” Su famosa prueba de Turing propuso que si una máquina puede mantener una conversación indistinguible de un humano, entonces puede considerarse inteligente.
En 1956, John McCarthy acuñó el término “inteligencia artificial” en la conferencia de Dartmouth. Desde entonces, la IA ha pasado por varios inviernos (períodos de poco financiamiento y escepticismo) y veranos (períodos de hype y avances).
El momento clave para los LLMs llegó en 2017, cuando un equipo de Google publicó el paper “Attention Is All You Need” (Vaswani et al.). Introdujeron la arquitectura Transformer, que permite procesar texto de forma paralela (no secuencial) y entender relaciones entre palabras sin importar la distancia entre ellas.
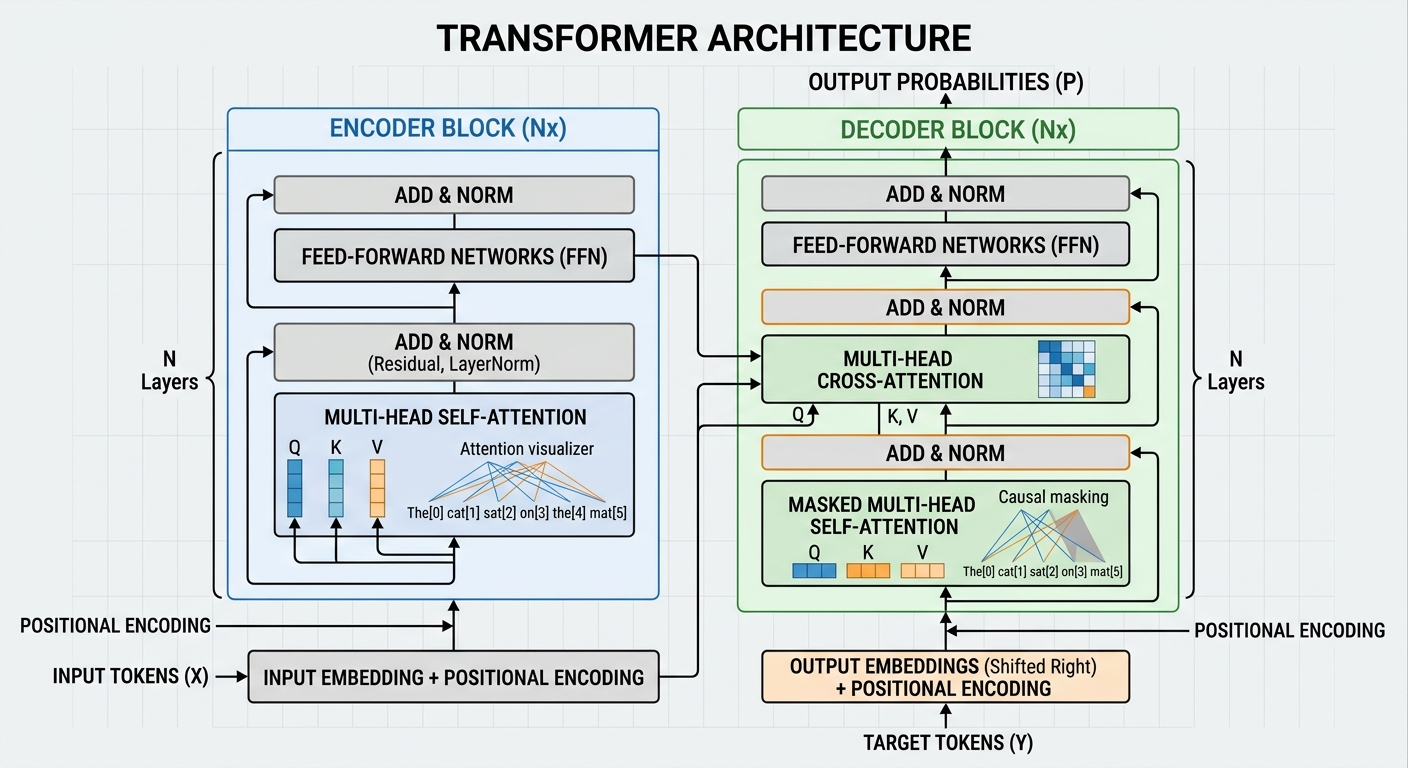
La arquitectura Transformer: el mecanismo de “atención” permite al modelo relacionar palabras sin importar la distancia entre ellas.
GPT (2018), BERT (2018), y todos los modelos modernos son variantes de esta arquitectura. El salto de GPT-3 (2020) a GPT-4 (2023) a GPT-4o (2024) muestra una aceleración que no tiene precedentes en la historia de la computación.
Por qué importa
Entender la IA no es opcional para un programador en 2026. No necesitas ser experto en machine learning, pero sí necesitas:
- Saber qué puede y qué no puede hacer un asistente de IA.
- Usarlo productivamente sin depender de él ciegamente.
- Mantener tu criterio técnico — la IA sugiere, tú decides.
- Entender los riesgos — privacidad, sesgos, desinformación.
La IA es como tener un colega junior increíblemente rápido que lee todo internet pero a veces inventa cosas. Úsalo como asistente, no como reemplazo.
La IA y la IA (sí, en serio)
Lo bueno
- Aprender sobre IA usando IA: los LLMs son excelentes profesores de sus propios conceptos. Pídeles que expliquen transformers, fine-tuning o RAG.
- Experimentar con prompts: la mejor forma de aprender prompt engineering es practicando. Cada interacción te enseña qué funciona y qué no.
- Comparar modelos: prueba el mismo prompt en ChatGPT, Claude, Gemini y también en modelos chinos como DeepSeek, Qwen3.6 o GLM-5.1. Las diferencias te enseñan sobre las fortalezas de cada uno.
- Usar OpenRouter para experimentar: con una sola API key accedes a cientos de modelos. Es la forma más práctica de comparar sin crear cuentas en cada plataforma.
Lo que no debes hacer
- No confíes ciegamente en explicaciones técnicas de IA. Si te explica cómo funciona un algoritmo, verifica con documentación oficial.
- No uses IA para tomar decisiones arquitectónicas sin investigar. La IA puede sugerir patrones que suenan bien pero no son apropiados para tu caso.
- No asumas que la IA entiende tu contexto. Siempre proporciona la información relevante. “Mejora este código” sin contexto produce respuestas genéricas.
- No te quedes con un solo modelo. El ecosistema es enorme y competitivo. Explorar alternativas te da perspectiva y a veces resultados mucho mejores.
Desafío: tu primer asistente de IA
Objetivo: usar un asistente de IA para aprender algo nuevo y verificar la información.
Tu tarea:
- Elige un concepto de programación que no entiendas bien (puede ser algo de guías anteriores o algo nuevo)
- Pídele a un asistente de IA que te lo explique con una analogía y un ejemplo de código
- Verifica la información: busca en documentación oficial o en al menos dos fuentes independientes
- Si la IA cometió un error, documenta qué fue y por qué es incorrecto
- Escribe un pequeño programa usando lo que aprendiste
Bonus: compara la misma explicación en cinco asistentes diferentes — ChatGPT, Claude, Qwen3.6-Plus, DeepSeek y GLM-5.1. ¿Cuáles son las diferencias? ¿Cuál fue más claro? ¿Cuál fue más preciso? Usa OpenRouter para acceder a todos desde un solo lugar con una sola API key.
Para seguir explorando
- Attention Is All You Need — el paper original de los transformers (técnico, pero histórico).
- The Illustrated Transformer — explicación visual excelente de cómo funciona un transformer.
- Prompt Engineering Guide — recursos y técnicas para escribir mejores prompts.
- AI Snake Oil — libro sobre los límites reales de la IA, de Arvind Narayanan.
- OpenRouter — accede a cientos de modelos (incluyendo DeepSeek, Qwen3.6, Kimi, GLM-5.1) con una sola API. Tiene modelos gratuitos (
:free) y de pago. - DeepSeek API Docs — documentación oficial de DeepSeek, modelos open source y precios bajos.
- Qwen Documentation — documentación de la familia Qwen de Alibaba, con Qwen3.6-Plus como modelo flagship.
- Kimi Platform — plataforma de Moonshot AI, modelos multimodales con soporte de video y contexto largo.
- Zhipu AI / GLM — repositorio open source de la serie GLM, con GLM-5.1 como modelo actual para agentes inteligentes.
Resumen
- La IA es un campo amplio; los LLMs son modelos de lenguaje que predicen la siguiente palabra en una secuencia.
- Los LLMs no piensan — predicen patrones basándose en datos de entrenamiento.
- Alucinan: pueden inventar información con confianza. Siempre verifica.
- Los usos principales para programadores: explicar conceptos, debuggear, generar boilerplate, revisar código, escribir tests y traducir entre lenguajes.
- El prompt engineering es clave: sé específico, da contexto, pide formato, itera.
- La arquitectura Transformer (2017, Vaswani et al.) es la base de todos los LLMs modernos.
- Los modelos chinos (DeepSeek, Qwen3.6, Kimi, GLM-5.1) compiten de tú a tú con OpenAI y Anthropic, son open source y cuestan una fracción.
- OpenRouter te da acceso a cientos de modelos con una sola API, incluyendo modelos gratuitos (sufijo
:free) y de pago, con balanceo automático por precio y fallback transparente. - Los LLMs cobran por token (~¾ de palabra). El precio se calcula por millón de tokens, separado entre input y output. Con modelos chinos, una conversación completa cuesta fracciones de centavo.
- La IA es un asistente, no un reemplazo. Tu criterio técnico sigue siendo lo más valioso.
- Alan Turing planteó la pregunta “¿pueden pensar las máquinas?” en 1950. Hoy la respuesta es más matizada que nunca.
En la próxima guía vamos a saltar al Yellow Belt y explorar cómo funciona la web: HTTP, DNS y navegadores — qué pasa exactamente cuando escribes una URL y presionas Enter.