Cómo funciona la web: HTTP, DNS y navegadores
Qué pasa exactamente cuando escribes una URL y presionas Enter. Entiende los protocolos, servidores y navegadores que hacen posible la web.
Cada vez que escribes google.com y presionas Enter, ocurre una coreografía de protocolos, servidores y máquinas que tarda menos de un segundo. Millones de líneas de código trabajan juntas para traerte esa página. Y si eres programador web, entender esta coreografía no es opcional — es la base de todo lo que vas a construir.
En esta guía vas a seguir el viaje completo de una petición web: desde tu teclado hasta el servidor y de vuelta a tu pantalla.
El viaje de una URL
Cuando escribes https://www.ejemplo.com/articulo en tu navegador, esto es lo que pasa:
- Tu navegador pregunta “¿dónde está www.ejemplo.com?” → DNS
- El DNS responde con una IP →
93.184.216.34 - Tu navegador se conecta a esa IP → TCP/TLS handshake
- Envía una petición HTTP →
GET /articulo HTTP/1.1 - El servidor responde con HTML →
200 OK+ contenido - Tu navegador renderiza la página → parsea HTML, CSS, ejecuta JavaScript
Vamos paso a paso.
DNS: la agenda de direcciones de internet
El DNS (Domain Name System) es como la agenda de contactos de internet. Traduce nombres legibles (google.com) a direcciones numéricas (142.250.80.14) que las computadoras entienden.
Cómo funciona la resolución DNS
Tu computadora → DNS de tu ISP → DNS Root → DNS .com → DNS ejemplo.com
? ? ? ? → 93.184.216.34- Tu computadora primero revisa su caché local. ¿Ya resolvió este dominio recientemente?
- Si no, pregunta al DNS recursivo (generalmente el de tu proveedor de internet o el de Google
8.8.8.8) - El DNS recursivo pregunta a los servidores root (hay 13 grupos en el mundo): “¿Quién maneja los dominios .com?”
- Los root le dicen: “Los servidores TLD de .com, aquí están sus IPs”
- El recursivo pregunta a los servidores TLD (.com): “¿Quién maneja ejemplo.com?”
- Los TLD responden: “Los nameservers de ejemplo.com, aquí están”
- El recursivo pregunta a los nameservers autoritativos de ejemplo.com: “¿Cuál es la IP de www.ejemplo.com?”
- Los nameservers responden:
93.184.216.34 - El DNS recursivo guarda la respuesta en caché y se la devuelve a tu computadora
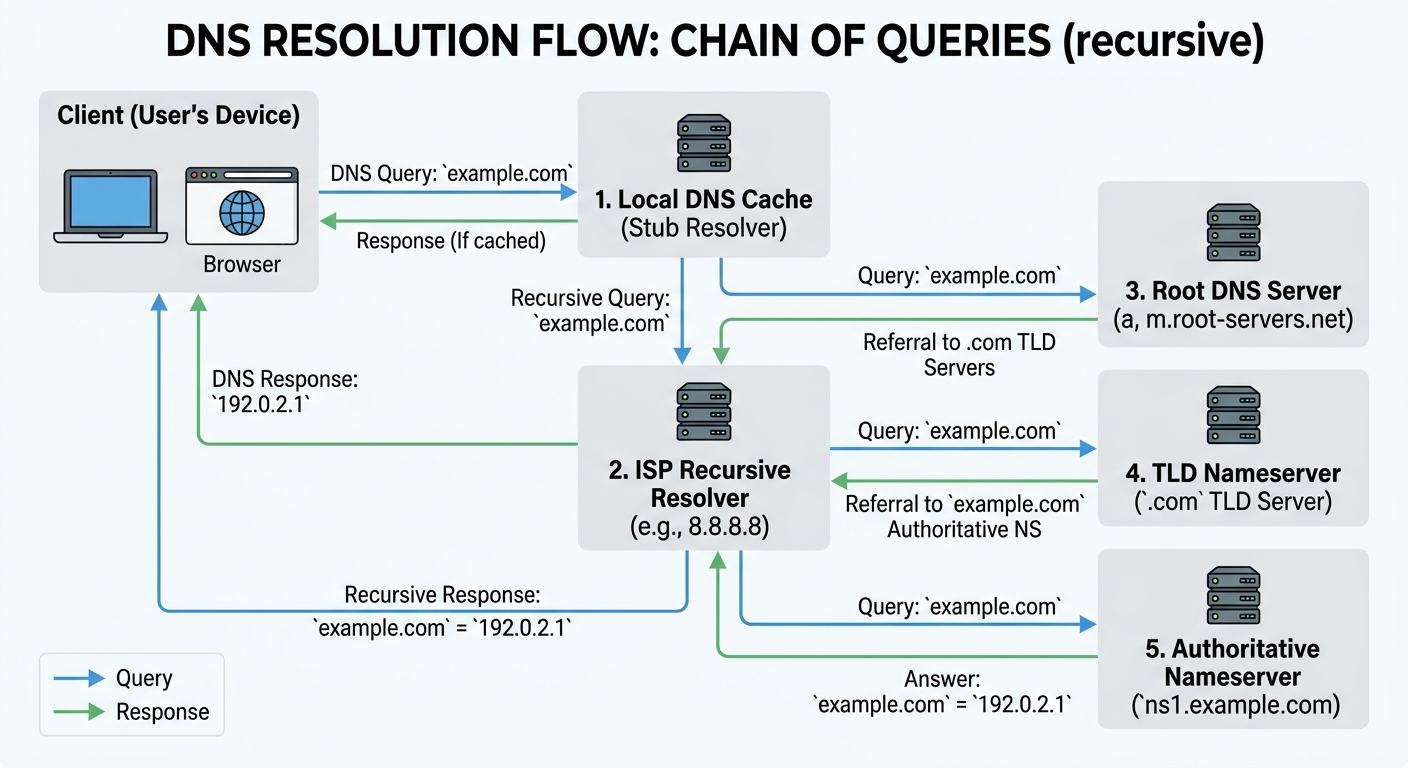
Resolución DNS: una cadena de consultas que convierte un nombre legible en una dirección IP.
Tipos de registros DNS
| Tipo | Para qué sirve | Ejemplo |
|---|---|---|
| A | IPv4 del dominio | 93.184.216.34 |
| AAAA | IPv6 del dominio | 2606:2800:220:1:248:1893:25c8:1946 |
| CNAME | Alias a otro dominio | www → ejemplo.com |
| MX | Servidor de email | mail.ejemplo.com |
| TXT | Texto arbitrario (verificación, SPF) | "v=spf1 include:_spf.google.com" |
| NS | Nameservers autoritativos | ns1.ejemplo.com |
Ver DNS desde la terminal
nslookup google.com # Consulta DNS básica
dig google.com # Consulta DNS detallada
dig google.com +short # Solo la IP
dig google.com MX # Registros de emailHTTP: el protocolo de la web
HTTP (HyperText Transfer Protocol) es el lenguaje en el que tu navegador y los servidores se comunican. Es un protocolo de petición-respuesta: el cliente pide algo, el servidor responde.
La estructura de una petición HTTP
GET /articulo HTTP/1.1
Host: www.ejemplo.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
Accept: text/html,application/xhtml+xml
Accept-Language: es-CL,es;q=0.9,en;q=0.8
Cookie: session=abc123Cada petición tiene:
- Método: qué quieres hacer (
GET,POST,PUT,DELETE, etc.) - URL: qué recurso quieres
- Headers: información adicional (idioma, cookies, tipo de contenido aceptado)
- Body: datos que envías (solo en
POST,PUT, etc.)
Los métodos HTTP
| Método | Acción | ¿Tiene body? | Idempotente? |
|---|---|---|---|
| GET | Obtener datos | No | Sí |
| POST | Crear recurso | Sí | No |
| PUT | Actualizar recurso completo | Sí | Sí |
| PATCH | Actualizar parcialmente | Sí | No |
| DELETE | Eliminar recurso | Opcional | Sí |
Idempotente significa que puedes hacer la misma petición mil veces y el resultado es el mismo. GET /articulo siempre devuelve lo mismo. POST /articulos crea un nuevo artículo cada vez.
La estructura de una respuesta HTTP
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 1234
Cache-Control: max-age=3600
Set-Cookie: session=xyz789; HttpOnly; Secure
<!DOCTYPE html>
<html>...</html>Cada respuesta tiene:
- Status code: qué pasó con tu petición
- Headers: metadatos (tipo de contenido, caché, cookies)
- Body: el contenido solicitado
Códigos de estado HTTP
| Código | Significado | Cuándo lo ves |
|---|---|---|
| 200 | OK | Todo salió bien |
| 201 | Created | Se creó un recurso nuevo |
| 301 | Moved Permanently | La URL cambió para siempre |
| 302 | Found (Redirect) | Redirección temporal |
| 304 | Not Modified | Usar la versión en caché |
| 400 | Bad Request | Tu petición está mal formada |
| 401 | Unauthorized | Necesitas autenticarte |
| 403 | Forbidden | No tienes permiso |
| 404 | Not Found | El recurso no existe |
| 500 | Internal Server Error | El servidor explotó |
| 502 | Bad Gateway | El servidor intermedio falló |
| 503 | Service Unavailable | El servidor está caído |
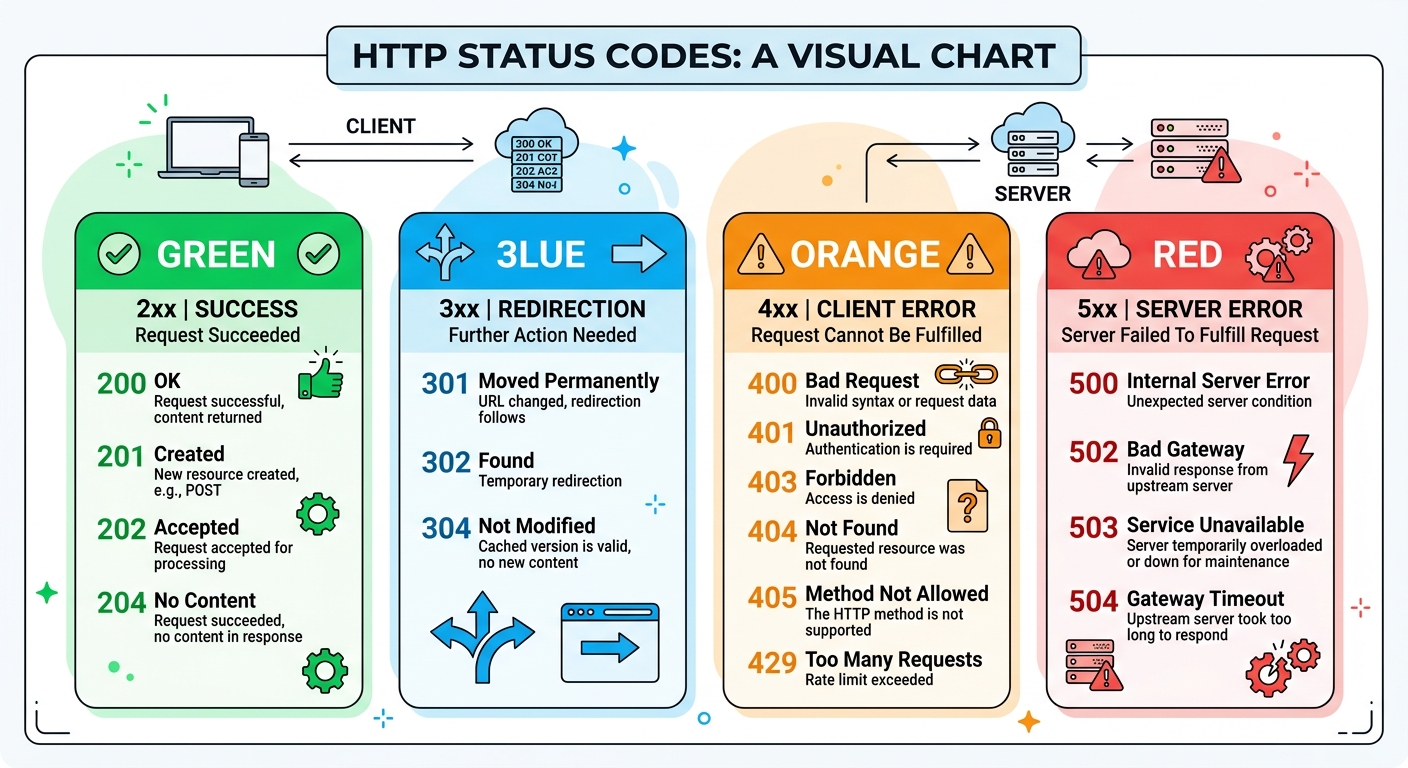
Los códigos de estado HTTP: cada rango cuenta una historia diferente sobre qué pasó con tu petición.
HTTPS: HTTP con seguridad
HTTPS es HTTP cifrado con TLS (Transport Layer Security). Sin HTTPS, cualquiera en la red puede ver lo que envías y recibes. Con HTTPS, la comunicación está cifrada.
El handshake TLS
Antes de enviar cualquier dato HTTP, tu navegador y el servidor hacen un “handshake” (apretón de manos):
- Tu navegador dice: “Hola, quiero conectarme de forma segura”
- El servidor responde con su certificado SSL (su identidad verificada)
- Tu navegador verifica que el certificado sea válido y emitido por una autoridad confiable
- Negocian un método de cifrado y generan claves compartidas
- A partir de ahí, toda la comunicación está cifrada
El candado 🔒 en tu barra de direcciones significa que este proceso fue exitoso.
El navegador: más que una ventana a la web
Tu navegador es un programa increíblemente complejo. Cuando recibe HTML de un servidor, hace mucho más que mostrarlo:
El proceso de renderizado
- Parsear HTML → convierte el texto en un DOM (Document Object Model), un árbol de nodos
- Parsear CSS → construye el CSSOM (CSS Object Model), un árbol de estilos
- Combinar DOM + CSSOM → crea el Render Tree (qué se ve y cómo)
- Layout → calcula la posición y tamaño de cada elemento
- Paint → dibuja los píxeles en pantalla
- Compositing → organiza las capas para optimizar animaciones y scroll
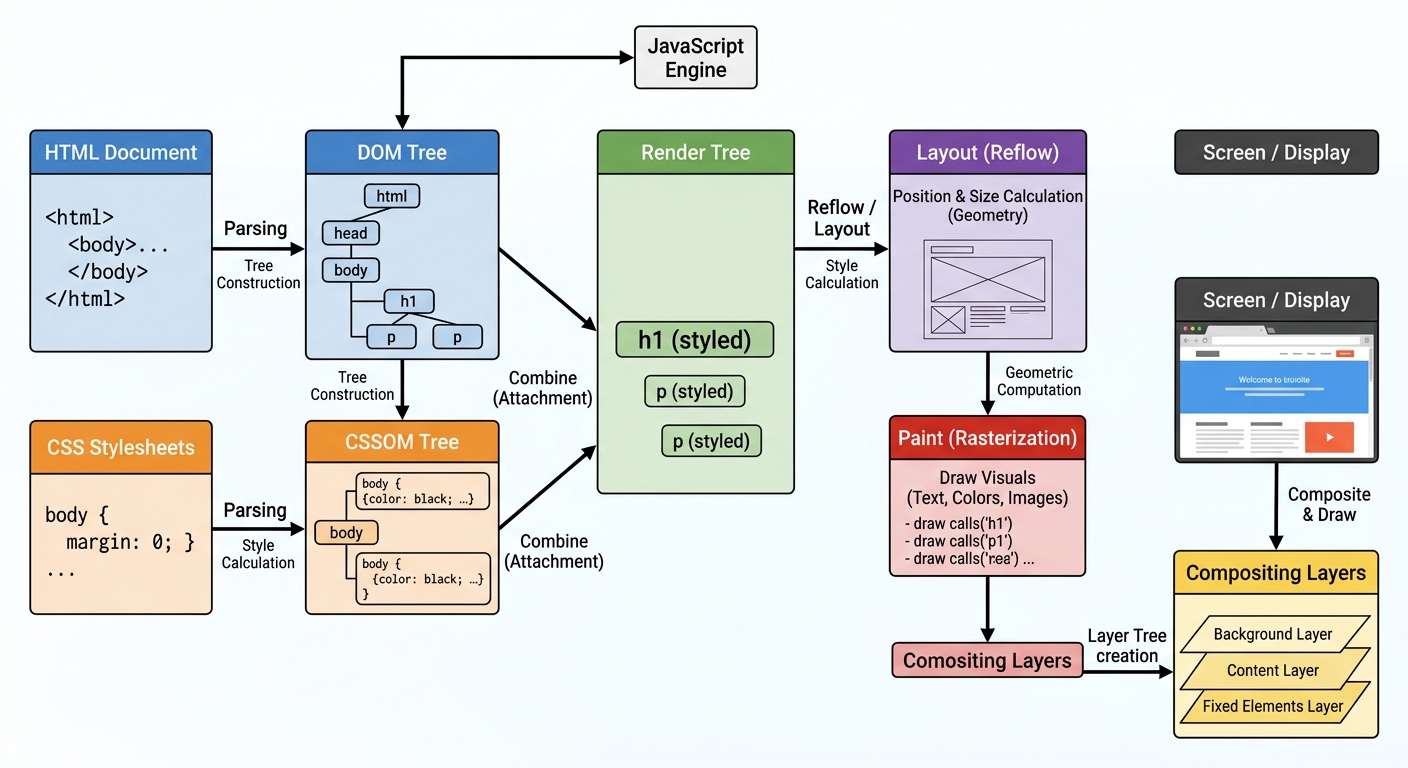
El pipeline de renderizado: de HTML crudo a píxeles en tu pantalla en menos de un segundo.
JavaScript en el navegador
Cuando el navegador encuentra una etiqueta <script>, pausa el renderizado, descarga el JavaScript, lo ejecuta, y luego continúa. Por eso los scripts pesados pueden hacer que una página se sienta lenta.
Por eso se recomienda:
- Usar
<script defer>para cargar sin bloquear el renderizado - Poner scripts al final del
<body>(práctica antigua, pero aún válida) - Minimizar el JavaScript que bloquea el renderizado
URLs: la dirección de todo en la web
Una URL (Uniform Resource Locator) es la dirección de un recurso en la web:
https://www.ejemplo.com:443/articulo/42?seccion=comentarios#top
│ │ │ │ │ │
│ │ │ │ │ └── Fragment (ancla)
│ │ │ │ └── Query string (parámetros)
│ │ │ └── Path (ruta del recurso)
│ │ └── Port (puerto, 443 es default para HTTPS)
│ └── Host (dominio)
└── Protocol (esquema)Componentes
- Protocolo:
http://ohttps://(tambiénftp://,mailto:,file://) - Host: el dominio o IP del servidor
- Puerto: por defecto 80 para HTTP, 443 para HTTPS
- Path: la ruta del recurso dentro del servidor
- Query string: parámetros clave-valor separados por
& - Fragment: una sección específica dentro de la página
Cookies, sesiones y estado
HTTP es un protocolo sin estado: cada petición es independiente. El servidor no recuerda quién eres entre una petición y otra. Para solucionar esto, existen las cookies.
Cómo funcionan las cookies
- El servidor responde con un header
Set-Cookie: session=abc123 - Tu navegador guarda esa cookie
- En cada petición posterior al mismo dominio, el navegador envía
Cookie: session=abc123 - El servidor lee la cookie y sabe quién eres
Las cookies modernas tienen flags de seguridad:
HttpOnly: no accesible desde JavaScript (protege contra XSS)Secure: solo se envía por HTTPSSameSite: controla si se envía en peticiones cross-site
Un poco de historia: de Tim Berners-Lee a la web moderna

Tim Berners-Lee en el CERN: donde inventó la World Wide Web en 1989.
La web fue inventada por Tim Berners-Lee en 1989 en el CERN (Organización Europea para la Investigación Nuclear). Su idea original era simple: los científicos del CERN necesitaban compartir documentos de investigación de forma eficiente.
Berners-Lee creó tres tecnologías fundamentales que siguen siendo la base de la web:
- HTML (HyperText Markup Language): el formato de los documentos
- HTTP (HyperText Transfer Protocol): el protocolo de comunicación
- URL (Uniform Resource Locator): el sistema de direcciones
El primer servidor web del mundo era una computadora NeXT en el CERN, con una nota pegada que decía: “This machine is a server. DO NOT POWER DOWN.”
La web original era solo documentos estáticos enlazados entre sí. No había imágenes (se agregaron en 1992), no había JavaScript (1995), no había CSS (1996). La web dinámica — con formularios, bases de datos, aplicaciones — vino después.
Hoy la web es la plataforma de software más grande del mundo. Mucha más que email, más que apps nativas. Y todo empezó con un documento de texto con enlaces.
Por qué importa
Entender cómo funciona la web no es conocimiento académico — es práctico todos los días:
- Debuggear: cuando algo falla, saber si es DNS, HTTP, o el navegador te ahorra horas.
- Performance: entender el renderizado te ayuda a hacer páginas más rápidas.
- Seguridad: saber cómo funcionan cookies y TLS te protege de vulnerabilidades.
- Arquitectura: diseñar APIs y servicios requiere entender HTTP a fondo.
- Debuggear en producción: leer logs de servidor, entender status codes, analizar headers.
No puedes construir bien sobre algo que no entiendes.
La IA y la web
Lo bueno
- Explicar protocolos: la IA puede desglosar HTTP, DNS, TLS con ejemplos y diagramas.
- Analizar peticiones: pega los headers de una petición HTTP y la IA te explica qué hace cada uno.
- Generar configuraciones: desde
.htaccesshasta headers de seguridad, la IA los genera rápido. - Debuggear errores de red: un error 502, un CORS bloqueado, un certificado expirado — la IA te guía.
Lo que no debes hacer
- No configures seguridad (TLS, cookies, CORS) solo con IA. Un error aquí expone datos de usuarios. Verifica con documentación oficial.
- No pegues headers con tokens o sesiones reales. Los cookies de sesión son credenciales.
- No asumas que la IA conoce la versión actual de los protocolos. HTTP/3, TLS 1.3 — los estándares evolucionan.
Desafío: rastrea una petición web
Objetivo: usar las herramientas del navegador para ver en detalle qué pasa cuando cargas una página.
Tu tarea:
- Abre cualquier página web en tu navegador
- Abre las DevTools (
F12oCmd+Option+I/Ctrl+Shift+I) - Ve a la pestaña Network
- Recarga la página (
Cmd+R/Ctrl+R) - Haz clic en la primera petición (el documento HTML) y examina:
- ¿Qué método HTTP se usó?
- ¿Cuáles son los request headers?
- ¿Cuáles son los response headers?
- ¿Qué status code recibió?
- ¿Cuánto tardó en responder?
- Haz lo mismo con al menos 3 recursos más (CSS, JavaScript, imagen)
- Usa la terminal para hacer
digdel dominio y anota cuántos servidores DNS se consultaron
Bonus: usa curl -v https://ejemplo.com en la terminal para ver la petición HTTP cruda, incluyendo el handshake TLS. Compara lo que ves con lo que viste en DevTools.
Para seguir explorando
- How Browsers Work — artículo profundo de Google sobre el proceso de renderizado.
- MDN — HTTP Overview — documentación completa de HTTP en español.
- DNS Explained — guía visual de Cloudflare sobre DNS.
- The First Website — el primer sitio web de la historia, aún online.
Resumen
- DNS traduce nombres de dominio a direcciones IP mediante una cadena de servidores (root → TLD → autoritativo).
- HTTP es un protocolo de petición-respuesta con métodos (
GET,POST,PUT,DELETE) y códigos de estado (200,404,500). - HTTPS agrega cifrado TLS sobre HTTP, protegiendo la comunicación con certificados SSL.
- El navegador parsea HTML → DOM, CSS → CSSOM, combina en Render Tree, hace Layout, Paint y Compositing.
- Las URLs tienen: protocolo, host, puerto, path, query string y fragment.
- Las cookies permiten mantener estado en un protocolo sin estado como HTTP.
- La web fue inventada por Tim Berners-Lee en 1989 en el CERN con HTML, HTTP y URL.
- Entender la web es esencial para debuggear, optimizar y construir aplicaciones correctamente.
En la próxima guía vamos a construir la base visual de toda página web: HTML y CSS: estructura y estilos — cómo se crean los documentos que los navegadores renderizan.